Jane Street


About
METR (pronounced ‘meter') is a nonprofit that evaluates frontier AI models to help companies and wider society understand AI capabilities and what risks they pose. To better understand what we do, take a look at these examples of our research.
- Measuring AI Ability to Complete Long Tasks
- Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
- MALT: A Dataset of Natural and Prompted Behaviors That Threaten Eval Integrity
- CoT May Be Highly Informative Despite “Unfaithfulness”



A Technical Challenge for the 3blue1brown audience
Optimize a GPU kernel—or try to "reward hack" your way to a high score. Just don't get caught by the AI reviewer.
The Kernel Optimization ChallengeFeatured work
Uplift Study
We conducted a randomized controlled trial (RCT) measuring how early-2025 AI tools affected the productivity of 16 experienced open-source developers working on large, mature codebases (avg. 5 years xp w/ repo). Developers completed 246 real issues, which were randomly assigned to either allow or disallow AI usage. Surprisingly, we found that when developers used AI tools, they took 19% longer—AI slowed them down. This contrasted sharply with both the developers' own expectations and expert forecasts (24% and 38-39% shorter time to complete tasks when allowed to use AI, respectively).
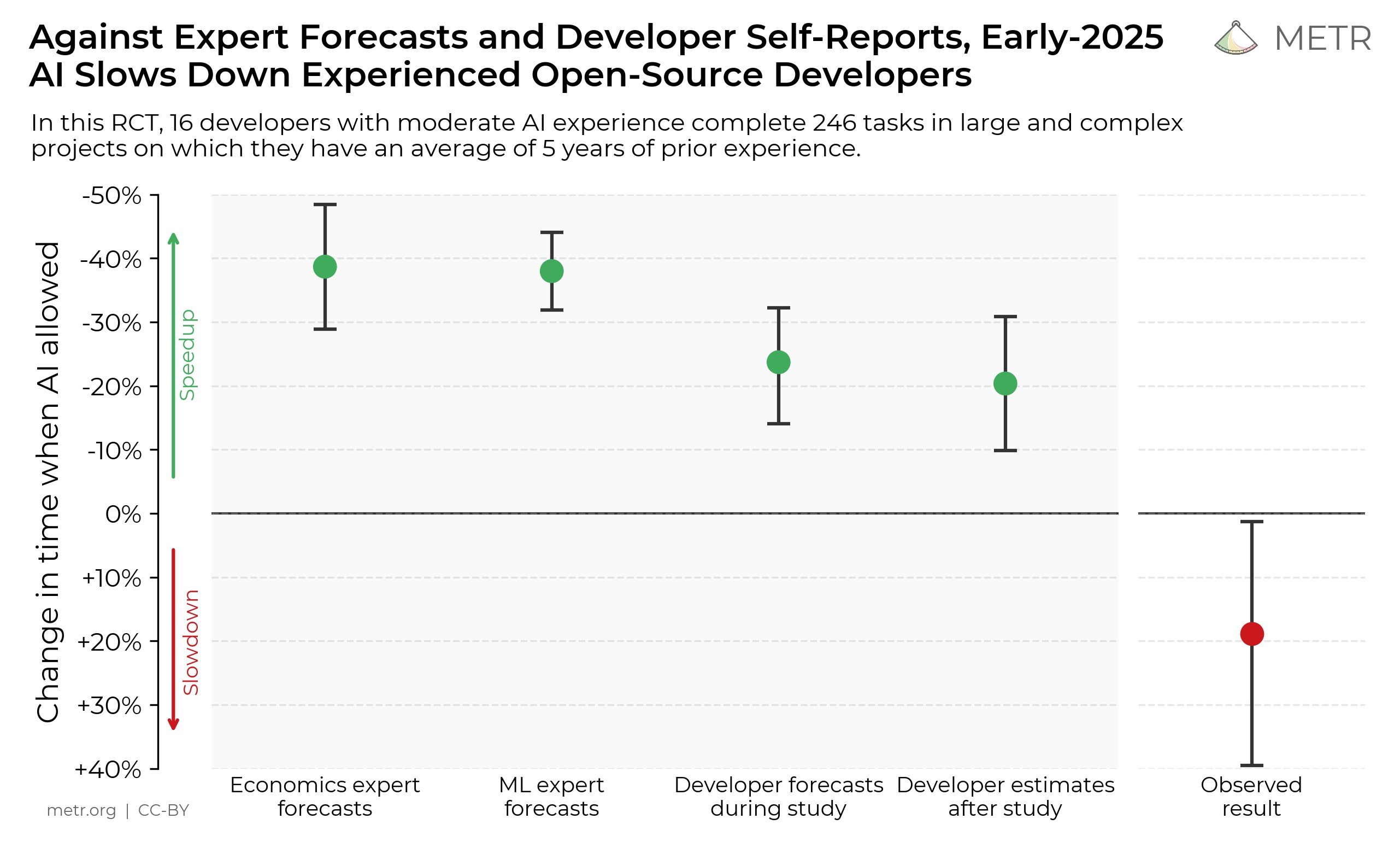
Read the full result
Time Horizon Study
We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
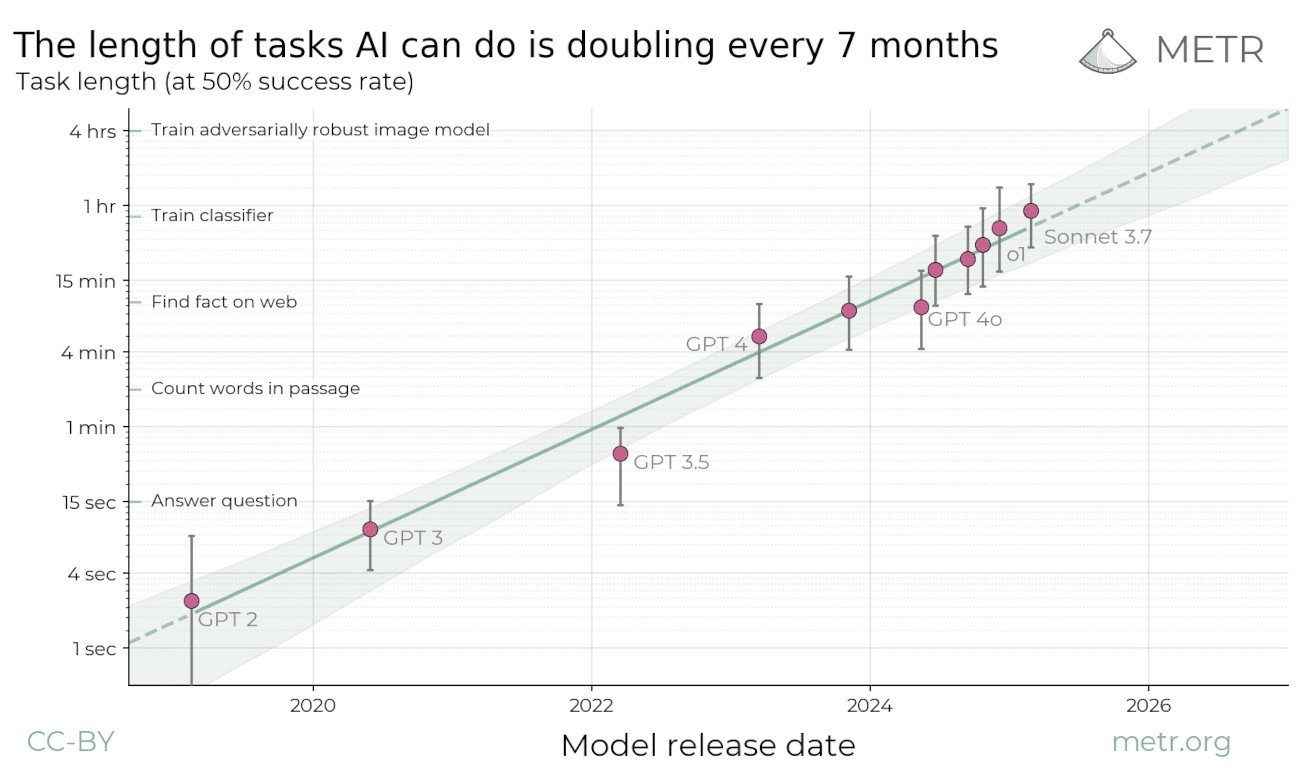
Read the full result